Rules, don’t double-vowel except self vowels. self vowels must be doubled in specific way. eg Hiragana, only a is self doubled. Rest: ioue are used at level 1. vowels can follow vowels for smooth follow, Hiragana: o almost always follows u,called u-don and so on. Indian double vowels ai, ou etc are not a good way. They are first of all incomplete, why not au eg? why stopped at ou? why ai and not ei? single vowels are enough [Hiragana does not use double vowel except for a only which is called level 2 vowel] level 1 vowel for all other vowels. level 0 for n. a special sound sometimes nasal and sometimes not. level 0 is called quick accent or halant in Indian. But Indian alphabet presently assigns all 3 levels to all vowels so 3*5=15 vowels and 2 additional from rru/rri [this vowel which is ambiguous plus a zero-level internally present in all consonants denoted here by _]rru/rri is actually a double consonant and single ambiguous vowel. [who knows may be double] also double consonants should not be there except when strictly defined, eg if only you want to write makka, k is a double consonant. This can be denoted by a special symbol for convenience but defining such for every other 2-3 combination types has created an unimaginably complicated system. Since consonants and vowels are a [~18]*5 romanized system
having 21 languages is not an excuse. Yesterday I was doing a off the top calculation which says there could be atleast as many as 12000 minimum phonetic elements instead of just 90 in India. Even 90 is more. Hiragana has 90, it abolished 22 unnecessary objects to form 68 characters/phonetics. These then can be accomodated by 22-reduction to 46 by recognizing that these phonetics could be similar among themselves. eg shi and ji are similar sounds hence represented by symbols that differ only by a small 2-strokes, and in some cases eg ho and po and bo by 2-strokes or a dit. I mapped the Indian alphabet system and called it Indougana. Here then we have almost all phonetics of India mapped into Hiragana. The only phonetics missing is perhaps vowel a with level 1. The level 0 must be avoided altogether and only put if completely necessary eg in a foreign sound like English. We do not respect ou language, we have mixed it with phonetics from Europe. Thats fine but a special chart should be made to do that. One should not define eg 3 sounds on C. [cerebral, canada, chicken and while taking the c sound from chiken why we took ch? it created further h-pseudofication, phonetics experts do not understand simple things before prescribing an unified system for the world]. SO there is extraneous mixing and there is self mixing. eg thrugh c, z/j/ch, s/sh and so on. s and sh will produce mixing of s+h. when they split there will be multiple words from same word and words won’t be recognized and so on. Also notice x defined to be ksh will do this much more with k,s,h splitting. So there is all sorts of mixing in teh alphabet and then we inherit phonetics or simply symbols for fun lets say from Romania or Mexico, then they are introduced into the native alphabets in various ways. Once there is a base alphabet with a Hiragana like minimal system [46+a few more lest say 18, or simply abolsih the level 2 a and have level 1 a. Then level 1 a will be double if necessar, never trippled. when we studied in high school we did not write too many letters for a word why we do that to Roman letters? We are uncivilized. We do not respect other’s sanity.]
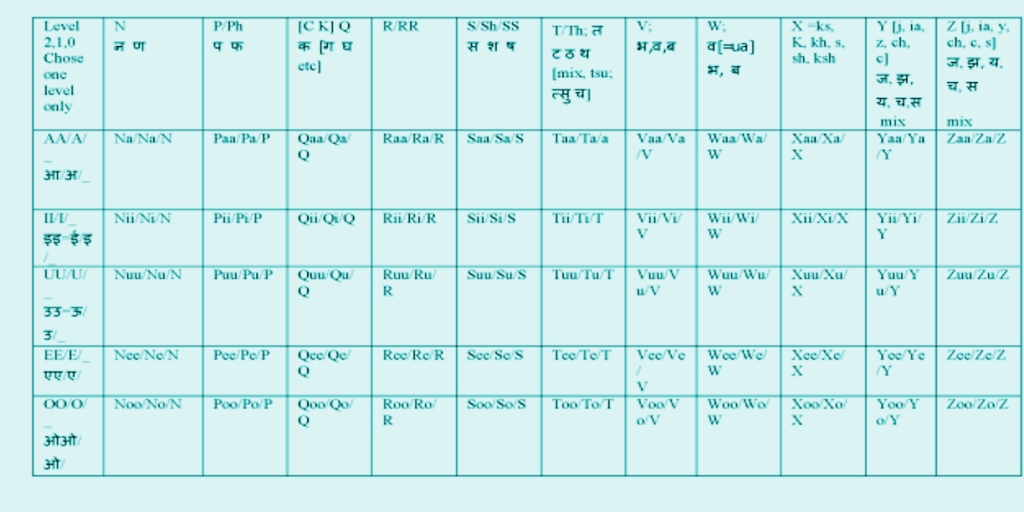
So all mixing and alternations should be studied which should fit into these two charts. Notice that this chart has tried to be somewhat comprehensive but you can put additional symbols to where they belong and use this for any of teh 21 languages because this is in terms of Hindi already. But you can also for great fun use the indougana. Also a good alphabet eg of hindi is simply 18 consonants and 5 vowels so 90 atmost of phonetics elements. Think, the world could learn all langauges of India by remembering only 90 or less [halved =46] and not 12000. Here goes the charts I promised a day or two ago.



Leave a comment